For over a decade I've been the person between design and engineering. The one who prototypes the idea before anyone else can see it, who builds the internal tools that unblock the team, who translates what a designer envisions into something that actually runs in a browser. I'm comfortable speaking both languages, and I've always enjoyed being the bridge.
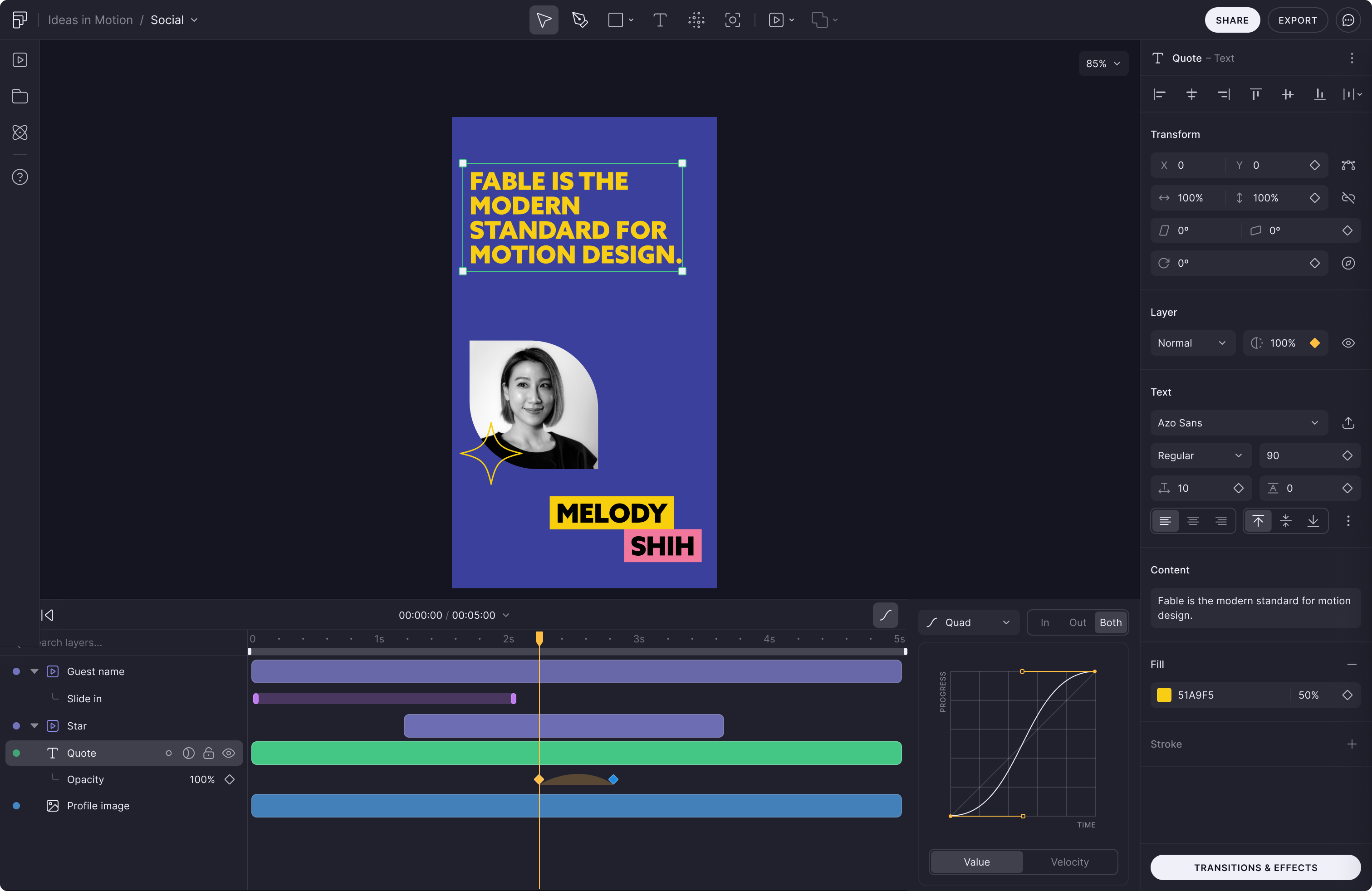
At Fable I built the rendering engine and designed the UI for the features it powered. As a freelancer I shipped award-winning interactive experiences that required both creative direction and deep technical execution. As an artist I build my own editors, my own generative pipelines, my own production systems, because the tools I need don't exist yet.
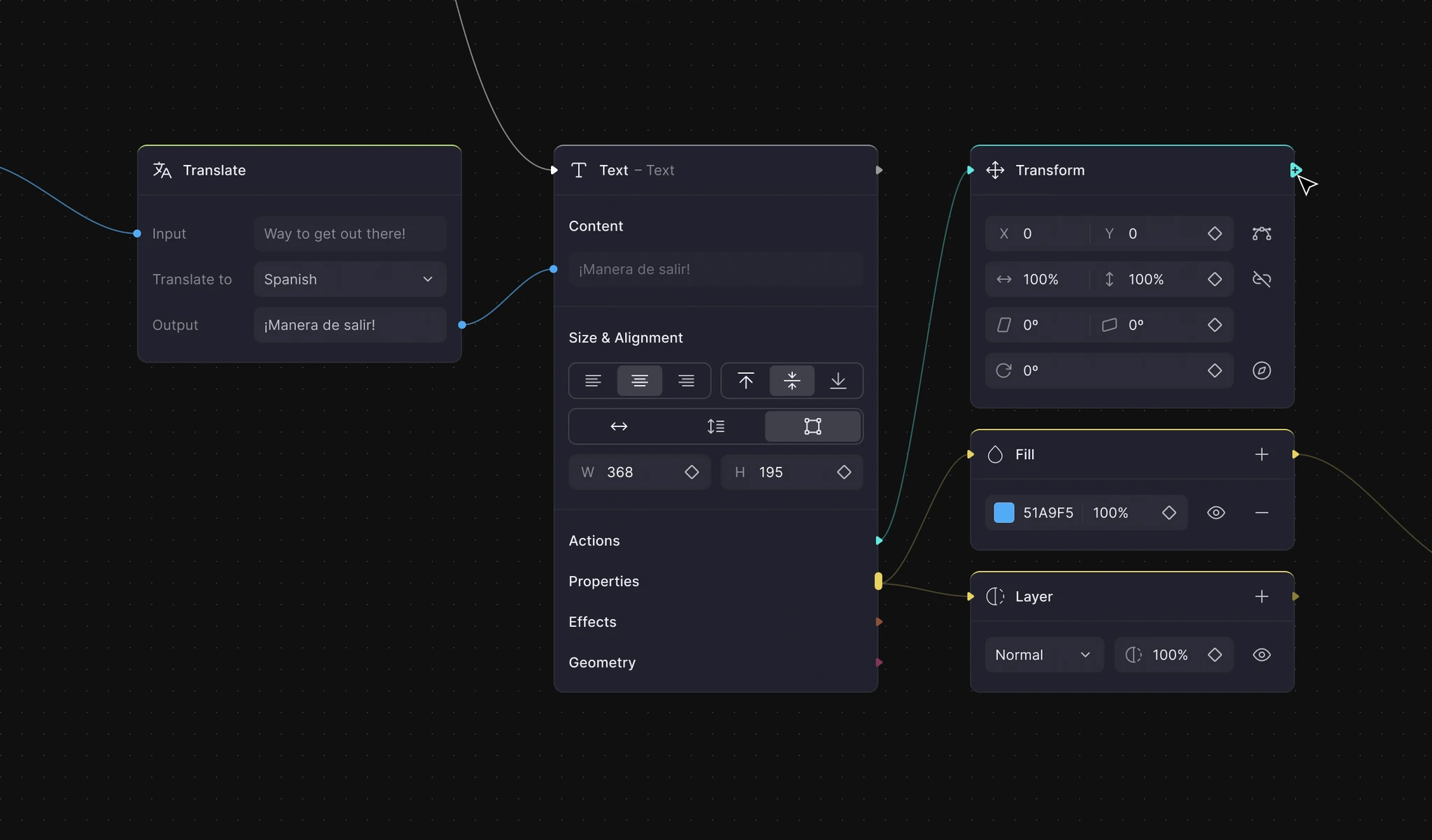
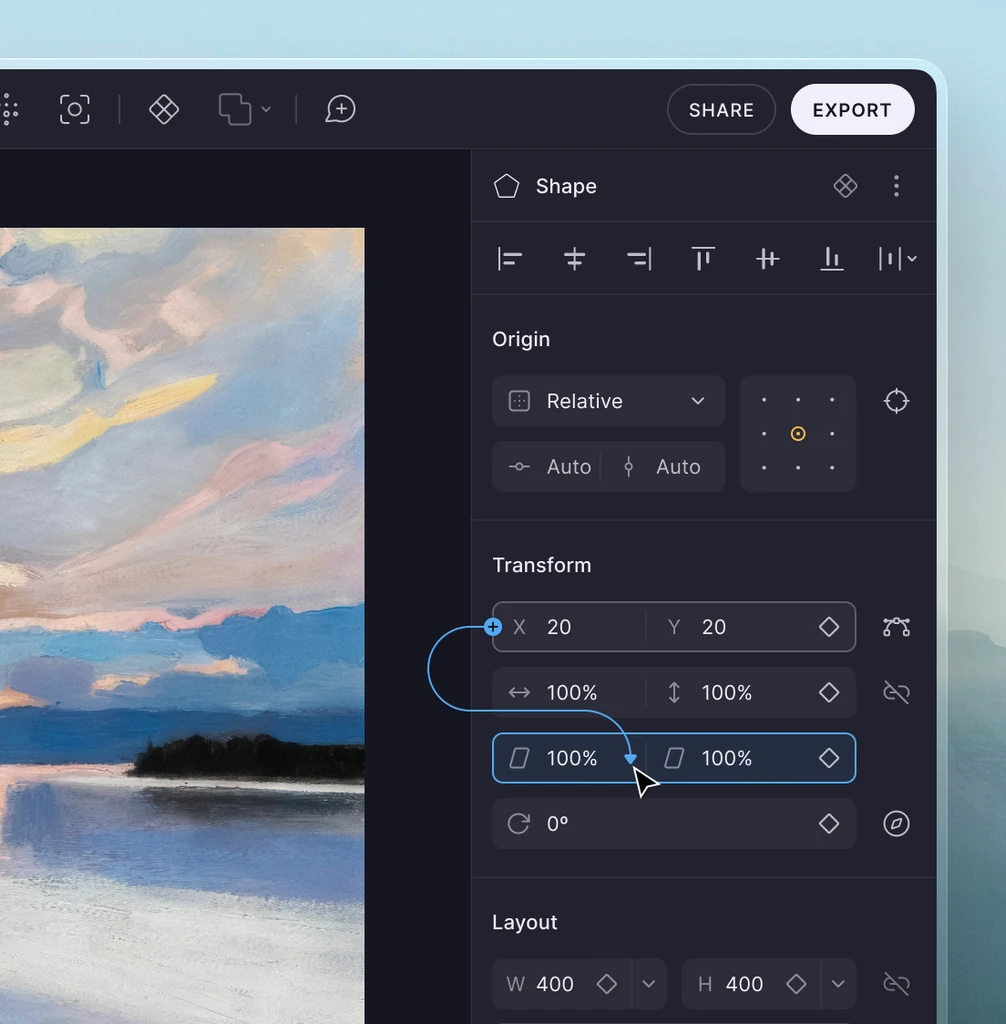
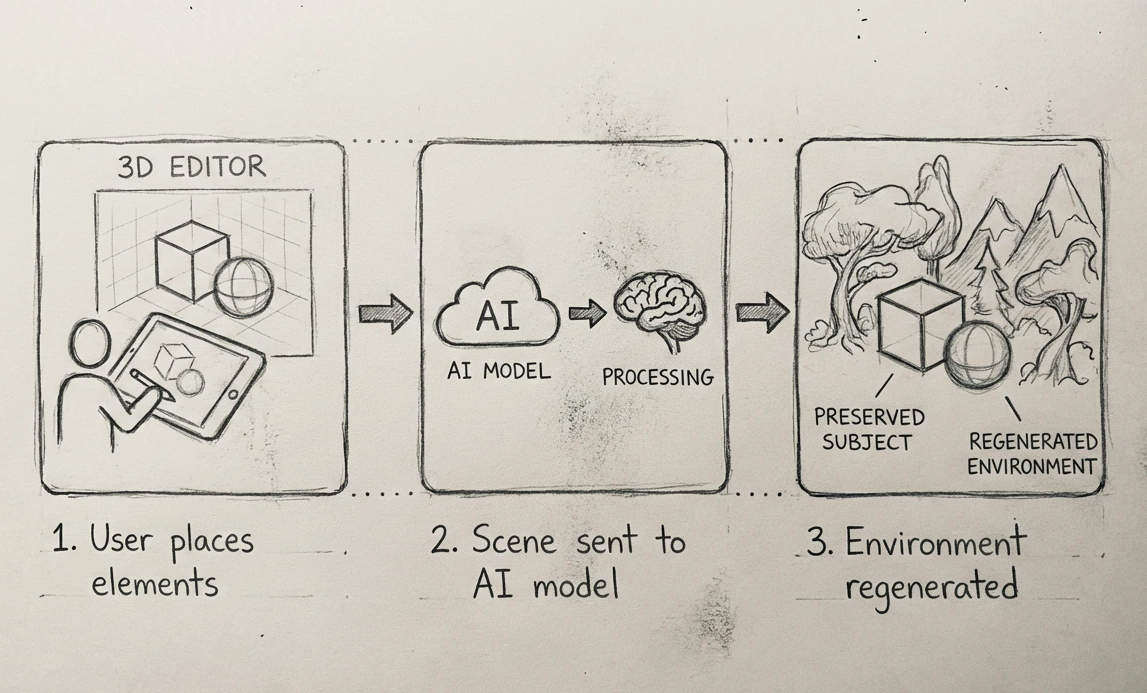
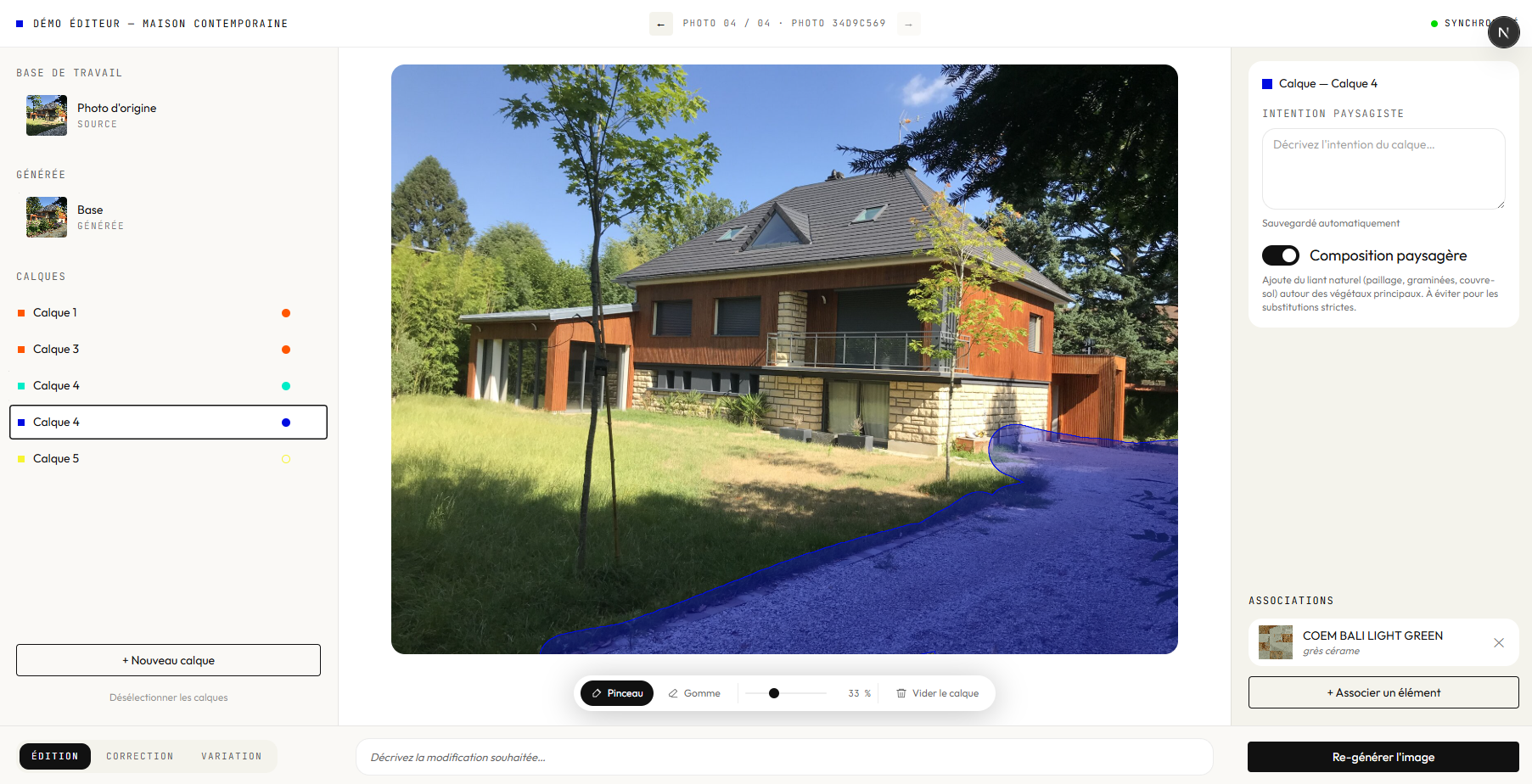
AI has amplified all of this. I now ship in hours what used to take weeks. I build interfaces where humans direct generative models with spatial, visual control, not just text prompts. From a 3D scene editor that lets users compose environments and send them to an AI model, to multi-model pipelines and AI-powered creative workflows I deploy for clients. My toolkit has expanded dramatically, but the core skill is the same: turning a vague creative intent into a working system, fast.
Reading about the Creative Technologist role at the Google Arts & Culture Lab felt surprisingly familiar. Prototyping interactive experiments at the crossroads of culture and AI, working from research and ideation through to fully-built web experiences, inventing new ways for people to access and engage with art. This is the work I care about most, the exact intersection of code, craft and culture I've spent over a decade in. It's also a kind of homecoming: Google's ecosystem is where some of my early work was first recognised (Google Creative Sandbox), where I've shipped commissioned work (real-time WebGL animations on the office screens at Google's Scramble Square in Shibuya), and whose generative models I now use daily. I'd love to help build what comes next.